AI EngineeringLLMEvalsPrompt Engineering
Eval-Driven LLM Systems: How I Improved Accuracy by 34% Without Changing the Model
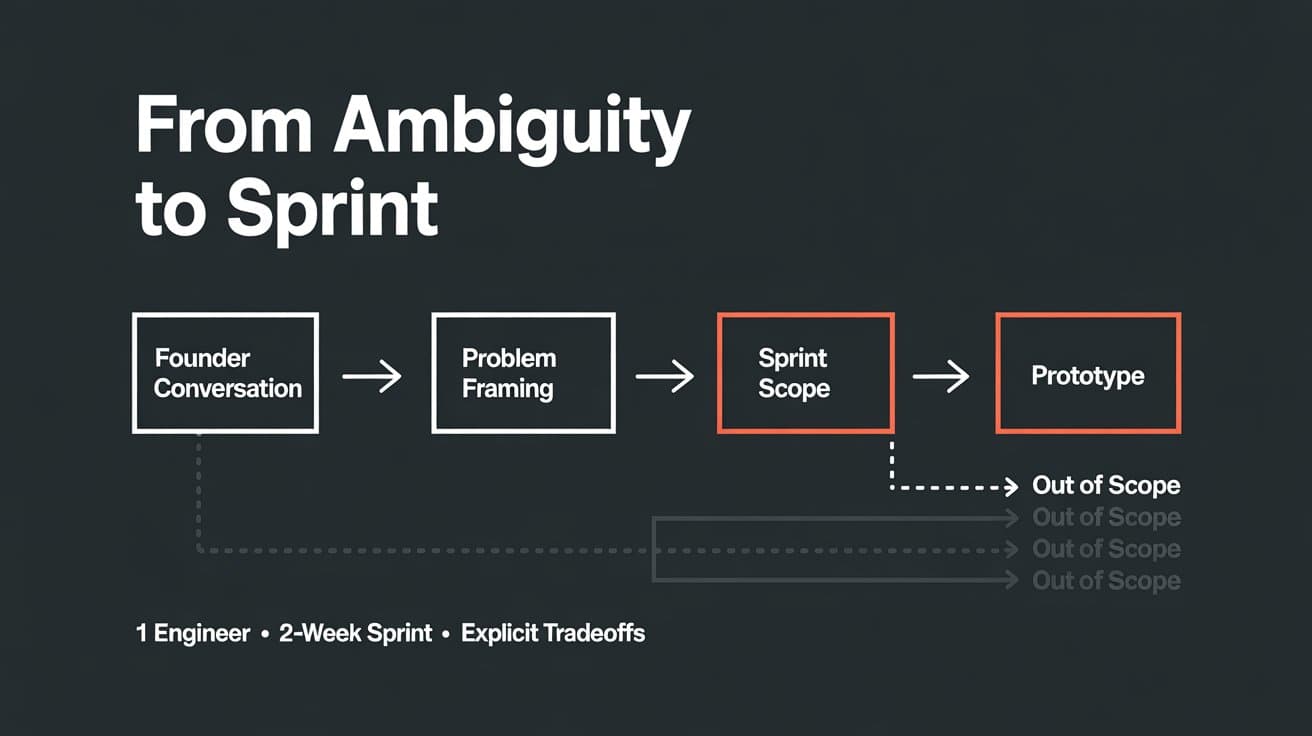
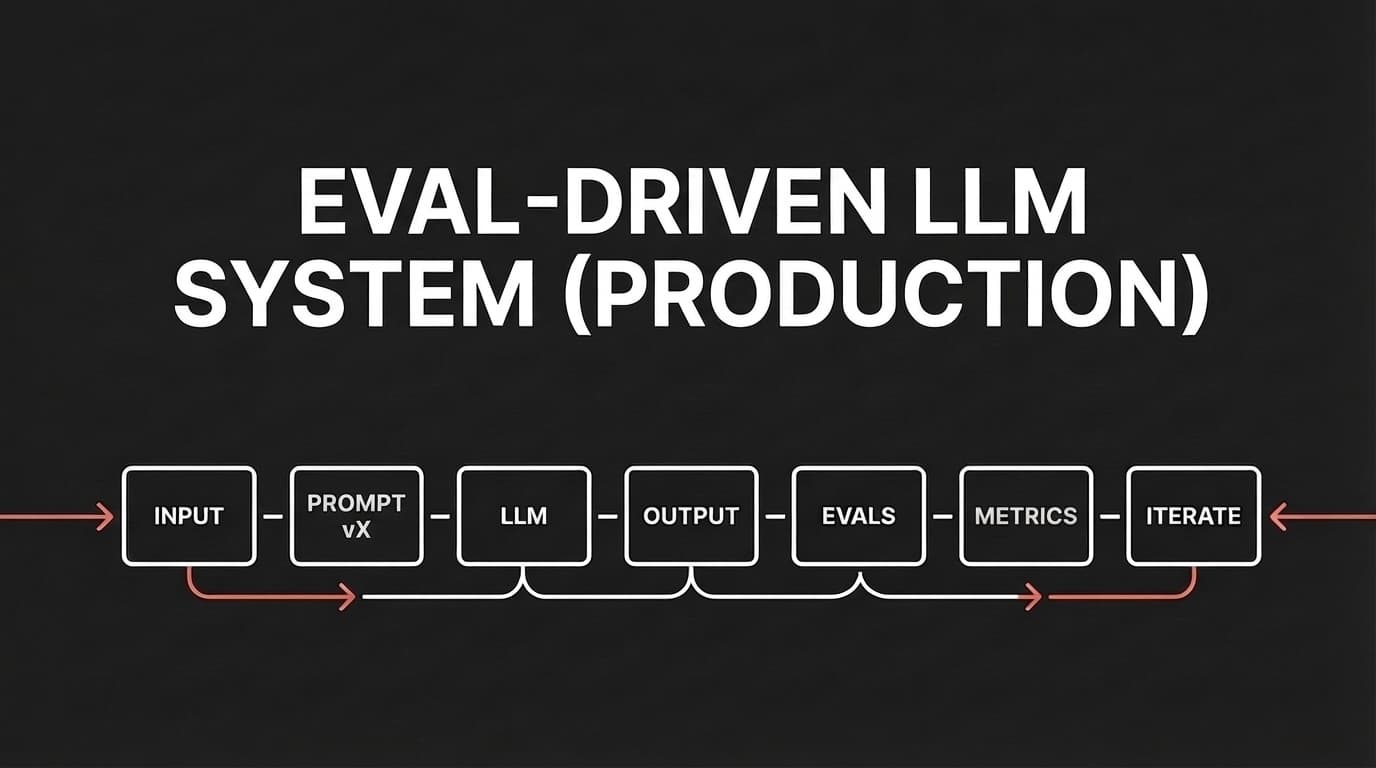
53% to 87% accuracy — without touching the model. This is the story of building an eval-driven LLM pipeline with prompt versioning, a golden dataset, and Braintrust. And why the cheaper model tied the expensive one.
March 2026•10 min read