Eval-Driven LLM Systems: How I Improved Accuracy by 34% Without Changing the Model
Prompt versioning, regression testing, and automated evals — the engineering loop that actually works
Full Repository (Code + Prompts + Dataset + Results)
https://github.com/PdroBrandao/eval-driven-llm-system
The Problem With LLMs No One Talks About
LLMs fail silently.
There's no exception. No stack trace. No alert.
The model just returns something - and you're supposed to trust it.
In a legal AI system extracting structured data from court notifications, a silent failure isn't a UX problem.
It's a missed deadline. A lawsuit. A liability.
So the real question isn't "which model should I use?"
It's: "how do I know if my system is actually working?"
The answer is an eval-driven pipeline. This is the story of building one.
The Setup
The system's job was simple: read raw legal notification text and extract structured fields (deadline, procedural class, instance, recommended action) as a JSON response.
The input is messy, the rules are domain-specific, and the model doesn't know Brazilian legal procedure.
Without a feedback loop, you have no idea if a prompt change helps or hurts.
So I built one.
The Loop
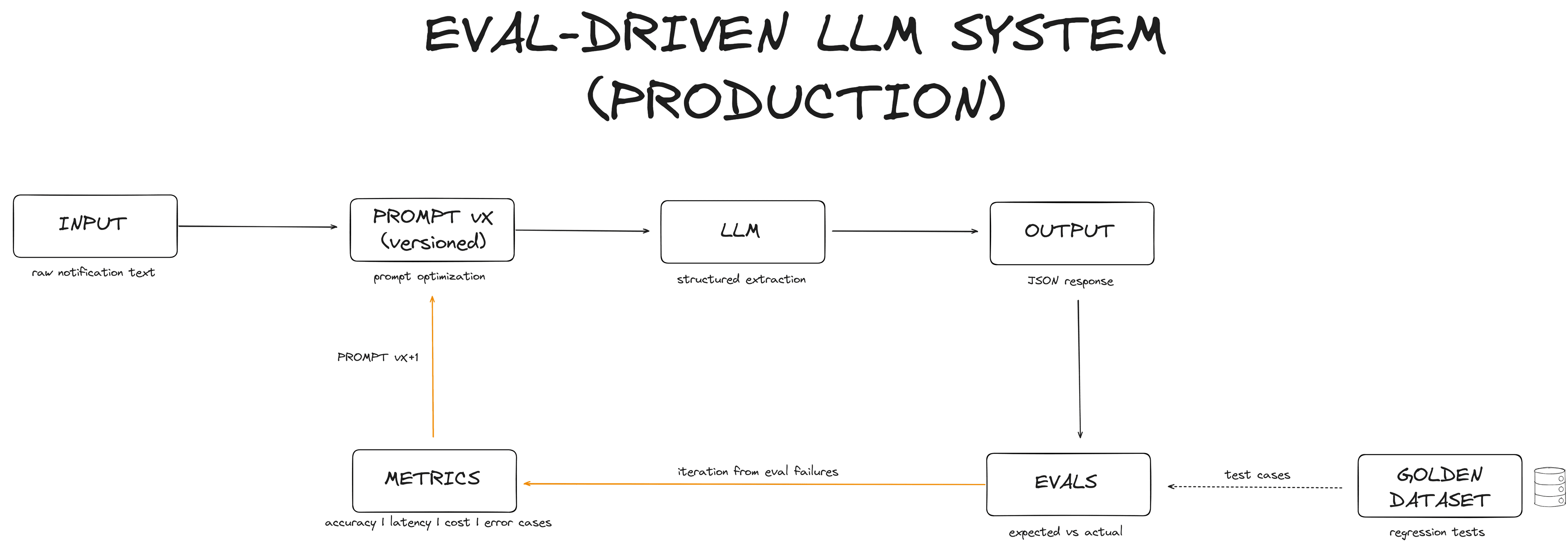
- Input - raw court notification text
- Prompt vX - versioned, tracked, with a changelog
- LLM - GPT-3.5-turbo or GPT-4o-mini
- Output - structured JSON
- Evals - validated against a golden dataset (30 regression cases)
- Metrics - accuracy · confidence · latency · cost · tokens
- Iterate - fix what's wrong, bump version, repeat
The Golden Dataset
The foundation of the whole system is a fixed set of 30 test cases, organized across 4 categories that map to the real failure modes:
| Category | What It Tests |
|---|---|
| deadlines/ | Correct extraction of legal deadlines (calendar days, court-specific rules) |
| procedural_category/ | Civil, criminal, labor, small claims classification |
| instance/ | First vs. second instance identification |
| recommended_actions/ | What the lawyer must do: appear, file response, take notice |
Each case has:
- Input: real notification text
- Expected output: the correct structured JSON
This is regression testing, applied to LLMs.
Every prompt change runs against the same 30 cases. You see immediately if something improved or regressed.
Prompt Versioning
Six prompt versions. Each one fixing a specific failure identified from the previous eval run.
| Version | What Changed |
|---|---|
| v1.0 | Baseline - first functional prompt |
| v1.1 | Added handling for "Pauta de Julgamento" edge case |
| v1.2 | Improved "Juizado Especial" identification |
| v1.3 | Removed unnecessary flags causing noise |
| v1.4 | Fixed false positive - model was confusing "awaiting hearing" with "hearing scheduled" |
| v1.5 | Added few-shot examples for recommended actions + restructured instructions |
This isn't prompt tweaking. It's prompt engineering.
Every version exists because a specific failure was identified, measured, and fixed.
One Error, One Fix
"Structured error analysis" sounds methodical. Here's what it actually looks like.
Input - a real notification text:
v1.0 output - wrong
{
"tipo_comparecimento": "aguardando pauta",
"data_comparecimento": null
}v1.5 output - correct
{
"tipo_comparecimento": "audiência designada",
"data_comparecimento": "15/03/2025"
}The model confused "hearing scheduled" with "awaiting hearing schedule" - two distinct legal states with completely different implications for a lawyer's workflow.
v1.0 had no examples of this distinction. The instructions described the fields but never showed the model where the boundary was.
v1.5 added a few-shot example for exactly this pattern - a concrete input/output pair showing a scheduled hearing. The model stopped guessing and started matching.
This is what structured error analysis means: identify the specific failure, understand why the prompt failed to prevent it, fix that gap explicitly. Not "improve the prompt" - fix the exact hole.
The Results

| Experiment | Accuracy | Confidence | Latency | Total Tokens |
|---|---|---|---|---|
| v1.0 · GPT-3.5 | 53.33% | 76% | 4.6s | 3,957 |
| v1.0 · GPT-4o-mini | 53.33% | 87.33% | 4.6s | 3,592 |
| v1.5 · GPT-3.5 | 86.67% | 79% | 5.1s | 5,022 |
| v1.5 · GPT-4o-mini | 86.67% | 88.33% | 5.4s | 4,517 |
+34% accuracy improvement - without changing the model.
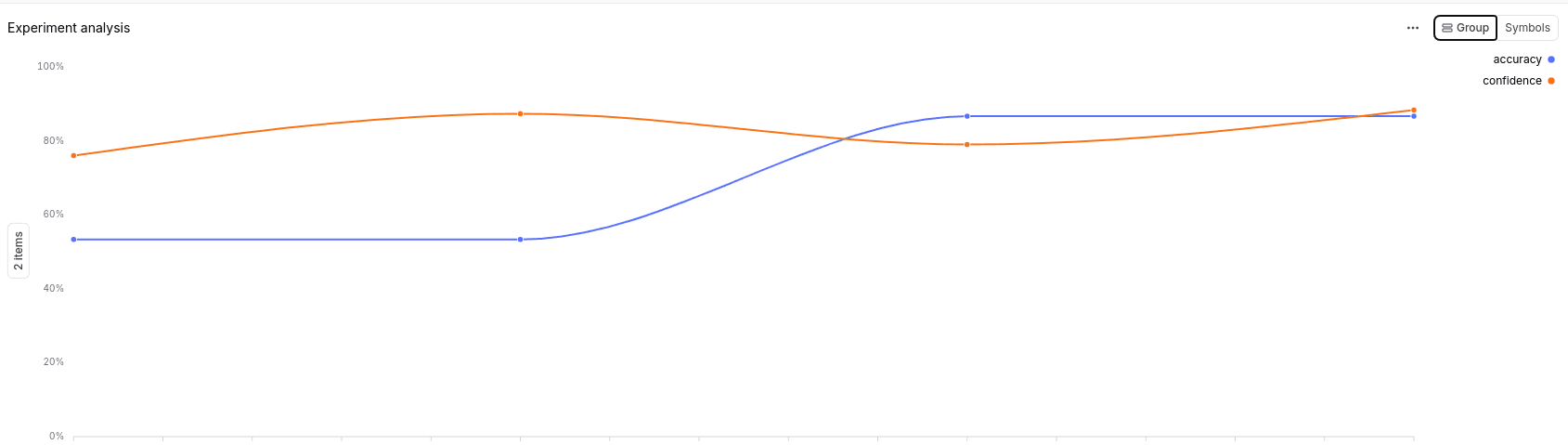
This pattern - versioned prompts, a fixed regression dataset, automated scoring before shipping - has a name. Engineering teams at companies like Stripe, Vercel, and Notion call it eval-driven development. I arrived at it by trying to solve a real production problem.
4 Insights Worth Defending
1. Prompt engineering > model upgrade
v1.5 · GPT-4o-mini (86.67%) outperformed v1.0 · GPT-3.5 (53.33%).
The prompt did what the model upgrade was supposed to do.
The newer, cheaper model with a better prompt beats the older, more expensive model with a weak one. Before reaching for a bigger model, invest in understanding why the current one is failing. The answer is almost always in the prompt - not the model.
2. For rule-based extraction, the model hits the ceiling set by the prompt - not by its own capability
With v1.5, both GPT-3.5 and GPT-4o-mini scored exactly 86.67% - 26 out of 30 cases. With v1.0, GPT-3.5 (the more expensive model) only reached 53.33% - 16 out of 30.
Two models. Same prompt. Same score. The model wasn't the variable.
In structured extraction tasks with deterministic rules - "is this a deadline? which court instance?" - model intelligence is not the constraint. Instruction precision is. When you give the model clear, unambiguous instructions, both converge to the same result regardless of price tier.
3. Prompt quality unlocks model choice - and cost
Both GPT-3.5-turbo and GPT-4o-mini hit exactly 86.67% with v1.5. GPT-4o-mini costs ~70% less per call.
Once the prompt is right, model selection is a finance decision, not an engineering one.
At 1,000 docs/day: ~$12/year on GPT-4o-mini vs ~$37/year on GPT-3.5-turbo - same accuracy, no quality trade-off.
The naive path when accuracy is low: upgrade the model. The eval-driven path: engineer the prompt, then pick the cheapest model that holds the result.
4. Iteration beats optimization - but only with a feedback loop
v1.1 through v1.4 each fixed real things: a false positive here, a misclassified instance there. But aggregate accuracy stayed flat at ~53% across all four versions.
I fixed four things. Nothing moved. Then I measured everything - and one real fix changed everything.
The leap came at v1.5 - not because of one small fix, but because of a more fundamental restructure: clearer instruction hierarchy, few-shot examples built from real production failures, and regression tests protecting what already worked.
The lesson: fixing edge cases without measuring aggregate impact is noise. You need a fixed dataset, a consistent metric, and the discipline to only ship what moves the number.
You can't optimize what you don't measure.
LLMs aren't "set and forget" systems.
They require continuous evaluation, iteration, and control of failure modes.
Closing
The goal wasn't to build the best LLM system.
It was to build a system that knows when it's failing - and has a process to fix it.
Eval-driven development is how you take LLMs from demo to production.
Not bigger models. Not more prompting.
Measurement. Iteration. Control.
📂 Full code, prompts, and dataset:
github.com/PdroBrandao/eval-driven-llm-system

Pedro Brandão
AI Product Engineer • LLM Systems (Production)