LLMs Aren't Magic: Lessons From Taking a Legal AI System From Chaos to Production
Real impact, real engineering, real lessons
Watch the Full Technical Demo
See the system in action: from architecture to production impact. This video complements the technical case study below.
Full Repository (Code + Metrics + Diagrams)
https://github.com/PdroBrandao/llm-legal-automation-production
Opening — Real Impact
Five months in production.
Over 3,000 court notifications processed.
99.22% success rate.
Average cost of $0.11 per lawyer per month.
More than 800 hours of manual work saved.
This is Intimação Pro —
a real system, running daily,
born from a simple, repetitive, inevitable problem…
that revealed far greater complexity than it seemed.
Let's dive into the journey.
Full production dashboards:
Production Impact (June - November 2025)
The Real Problem
Every Brazilian lawyer lives the same daily ritual:
- Open the Justice Diary.
- Read each notification.
- Determine the actionable next steps.
- Calculate the deadline.
- Write it down. Don't forget.
- Repeat tomorrow. And the next day. Forever.
30 minutes per day — in small offices.
Much more in medium-sized ones.
And the deadline?
It's not fixed. Not always written.
It depends on the court, the instance, the type of legal act.
Missing a deadline = financial loss, civil liability, chaos.
This pain is everywhere.
📎 Full "Problem & Solution" breakdown:
The Problem & Solution
There are 1.2M lawyers in Brazil.
If 0.5% adopt the solution, we're talking about an eight-figure annual business.
And that's where I came in.
How the Project Was Born
Simple conversation with a lawyer friend.
Him describing the operational chaos.
Me, my growing obsession with LLMs.
I asked a direct question:
"What's the simplest, highest-return process
that a lawyer does every single day?"
The answer was immediate.
- Fetch court notifications.
- Calculate deadlines.
Simple.
Repetitive.
Critical.
And completely neglected by existing technology.
The Initial Chaos — Real Story
Before architecture, reality hit hard:
- Municipal holidays.
- Different rules per court.
- Infinite edge cases.
- Poorly formatted text.
- Divergent instances and nomenclatures.
Before engineering came business domain:
weekly meetings, drawing legal decision trees,
and creating a deadline calculation algorithm
(which not even the lawyer himself had formalized before).
Before scope came the questions without a manual:
"Can I trust the Diary's API?"
"Do notifications arrive at a fixed time?"
"How much monitoring is needed?"
"How do I validate the LLM's interpretation if I'm not a lawyer?"
"What's the minimum scope to generate real value? Calendar? Trello? WhatsApp?"
No ready answers.
Just hypotheses.
And it became clear very early:
LLMs aren't magic.
LLMs are infrastructure.
An instrument in a larger orchestra.
Before being an AI Engineer, I had to be an engineer.
Good engineering is systemic — never just isolated tech.
Engineering → V0 Architecture
After the first weeks raising hypotheses and understanding the domain, I arrived at the first viable technical scope: a simple, stable architecture capable of running daily in production.
V0 Architecture — Serverless Monolith
🖼️ V0 architecture diagram (GitHub):
V0 — First Architecture
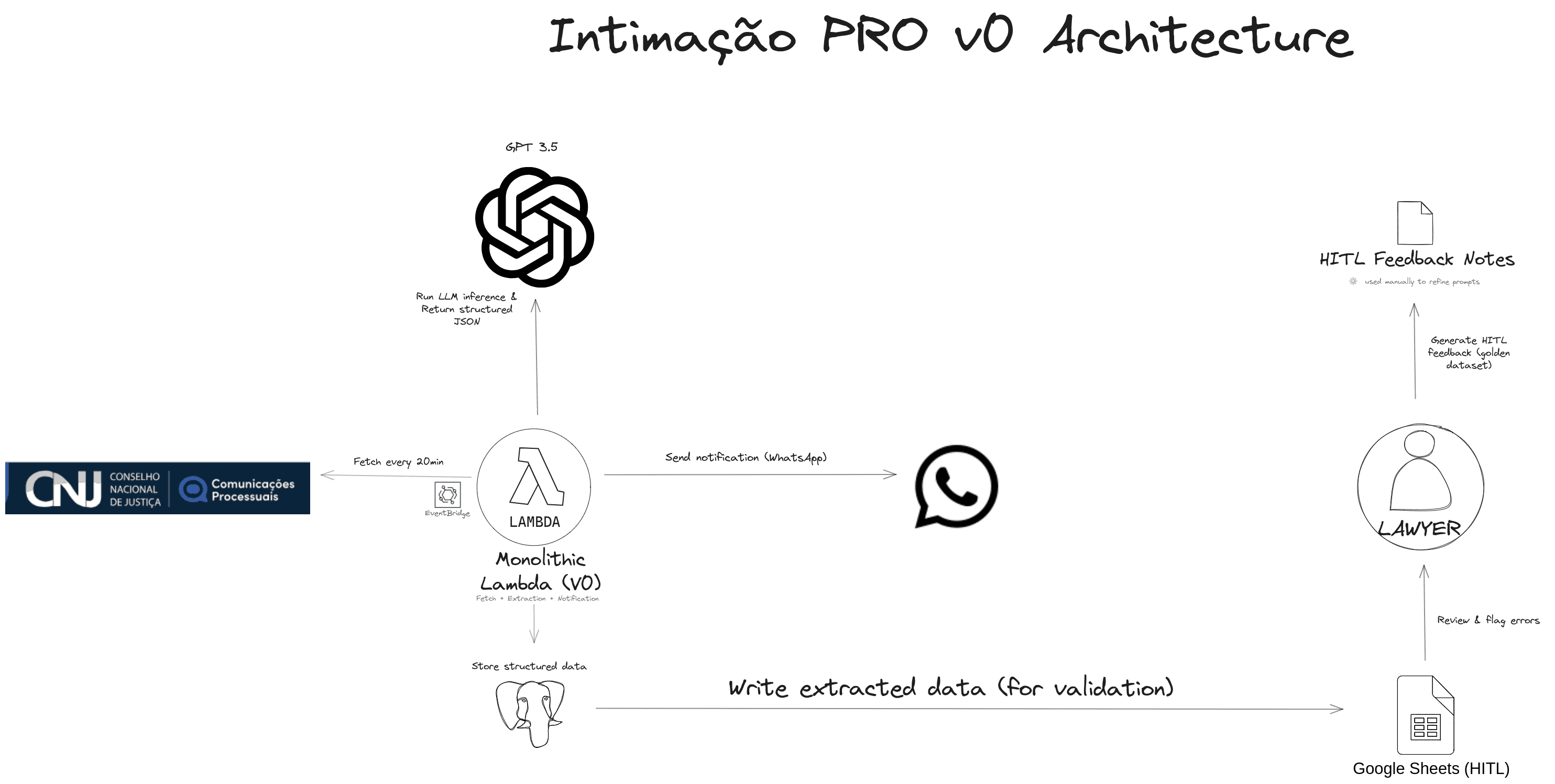
V0 was a monolith in AWS Lambda, triggered every 20 minutes via EventBridge.
It did everything:
- Fetch notifications from DJEN
- Run extraction using GPT-family models (optimized via prompt engineering and few-shot learning for high JSON conformity)
- Calculate deadlines
- Send WhatsApp notifications
- Log everything to a spreadsheet (HITL) via Google Sheets API for lawyer review
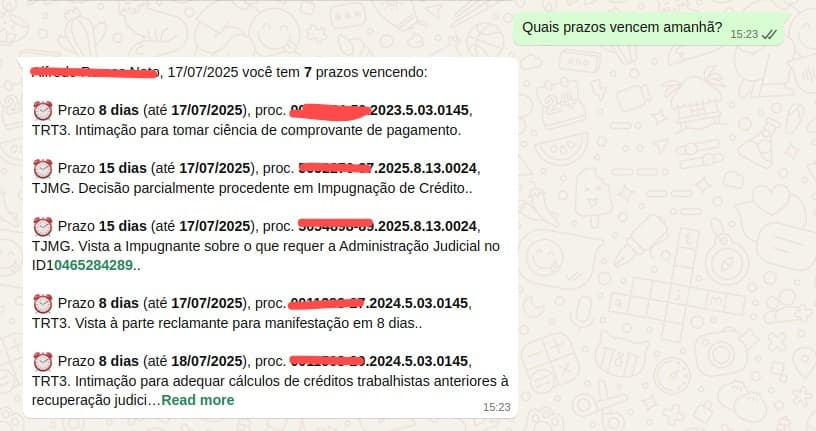
💬 WhatsApp agent screenshots:
WhatsApp Conversational Agent
"Why GPT-3.5?"
I chose GPT-3.5 for three practical reasons:
(1) immediate availability,
(2) unbeatable latency/cost for V0,
(3) mature JSON mode.
- - GPT-3.5: ~$0.0025 / analysis
- - GPT-4 (baseline): ~$0.0300 / analysis
Open-source models (Llama/Mistral) were valid options, but would require:
- tuning,
- hosting (vLLM/Groq),
- and a new observability layer.
For an MVP that needed to run in production within days, the operational cost was higher than the savings.
Pragmatism beat premature engineering.
I still didn't have full clarity on the legal rules — the deadline algorithm and field selection were being defined while the system was running.
First Engineering Pillars
To understand DJEN's behavior, I defined 1 week of observation:
- Logged success rate
- Logged latency
- Analyzed patterns by time and day of the week
I also prepared a set of previous notifications to accelerate Human-in-the-Loop, ensuring real case volume from the start.
I defined a base prompt for the lawyer to evolve via few-shot.
No theoretical explanation: just a good example → and it worked.
Now It Was Time to Test Simultaneous Hypotheses
- "Is it working every day?"
- "Can I trust DJEN?"
- "Is the daily volume enough to evolve the prompt quickly?"
- "Does this flow really deliver ROI?"
With the initial architecture in place and the operational checklist closed:
I prototyped.
I shipped.
And I let the production data do the talking.
Chaos in Production
The first weeks were… complete chaos.
The lawyer was correcting dozens of notifications per day.
I was receiving everything in red.
And there was — yet — no pattern, no taxonomy, no continuous improvement loop.
Questions That Emerged in the Fire
"Is it more scalable to teach a non-technical person to build the prompt…
or do I need to master all the rules and build it myself?"
"How will the lawyer validate a prompt update
if GPT-3.5 doesn't exist in OpenAI's web interface?"
"If he validates with GPT-4, won't that bias the results?"
"How do I evolve the prompt without breaking what already works?"
"How do I classify errors? Where do I start? How do I prioritize?"
"How do I measure accuracy if I don't even know yet what's right or wrong?"
"How do I organize multiple prompt versions before it becomes a mess?"
I Was Reinventing the Wheel. But the Wheel Had Technical Names:
- My text changelog → was Prompt Versioning (and every serious company uses it).
- The review spreadsheet → was Human-in-the-Loop (HITL) — global standard in critical systems.
- Cases reviewed by professionals → Golden Dataset + Regression Tests (the core mechanism to evolve models safely.)
🔍 See HITL flow, prompt changelog & eval results:
HITL & Prompt Evolution
At the time, I didn't know the names.
I was just trying to survive the chaos.
While I was trying to find the answers,
the volume of corrections kept multiplying.
And each new error brought a new hypothesis — and more engineering ahead.
Learning (the Hard Way)
Each chaotic question from the first weeks
ended up becoming an engineering principle.
"Good engineering is systemic — never just technical."
To be honest, I didn't really know the terms.
I had no idea I was reproducing advanced AI Engineering practices.
But I did it the artisanal way:
- Error classification.
- Prompt versioning.
- Human-in-the-loop.
- Regression testing.
- Golden dataset.
And only later discovered the names.
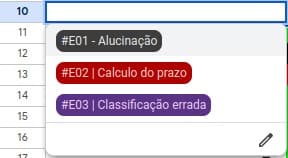
Error Classification
First step to organize the chaos:
name the problem.
I standardized everything into three categories:
- #E01 — Hallucination
- #E02 — Calculation error
- #E03 — Wrong classification
This simple structure unlocked clarity.
And clarity is oxygen in engineering.

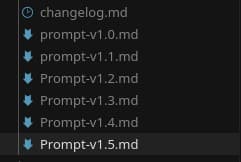
Prompt Versioning
We updated the prompt every week.
And without control, it would become a mess.
So I created:
- a changelog,
- numbered versions,
- modification history,
- link for each adjustment.
Simple.
And changes everything.
I believe the AI Engineer's "rite of passage" is this:
understanding that LLMs are black boxes — and that only metrics keep them under control.
Regression Testing (the Game Changer)
After a few weeks in production,
we finally had a minimum Golden Dataset — small, but representative.
Enough to create the first test suite:
- compare accuracy version to version,
- identify regressions early,
- measure latency, cost, and confidence,
- and, most importantly, protect what was already working.
This was the real beginning of our learning loop.
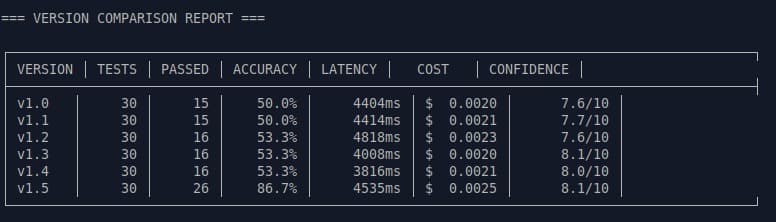
And when the numbers started appearing, the pattern was clear:
The first versions (v1.0 → v1.4) were stuck on the same plateau:
- 50% → 53% accuracy
- latency varying between 3.8s and 4.8s (stable p95, sufficient for non-interactive flow)
- confidence climbing millimeter by millimeter (7.6 → 8.0/10)
- stable cost, but no real evolution
Nothing broke.
Nothing improved.
Until v1.5 arrived.
🚀 The Leap: v1.5
After adjusting instructions, refining structure,
and adding few-shots from the most recurring errors — the breakthrough came.
📊 Version Evolution (Condensed View)
| Version | Accuracy | Deadline | Recommended Action | Cost/Analysis |
|---|---|---|---|---|
| v1.0–v1.4 | 50–53% | — | — | ~$0.0020 |
| v1.5 | 86.7% | 100% | 78.6% | $0.0025 |
📈 Accuracy evolution charts (v1.0 → v1.5):
HITL & Prompt Evolution
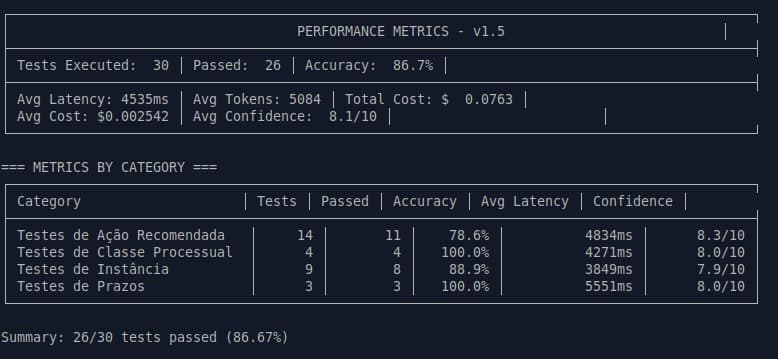
v1.5 Details
- 26/30 tests passing
- +33.3 pp accuracy in a single cycle
- Stable latency: ~4.5s
- Confidence: 8.1/10
- Cost per analysis: $0.0025
Metrics by Category (Where It Really Matters)
- Deadlines: 100%
- Procedural Class: 100%
- Instance: 88.9%
- Recommended action: 78.6% (the hardest category)
For the first time, the system went from "a prototype that works"
to a controlled, auditable, and predictable pipeline.
Result:
- more predictability
- more security
- less chaos
And, most importantly:
the feeling that the system was evolving — not by luck, but by engineering.
How I'm Evolving
Months in production made it clear:
the v0 architecture worked — but only to a point.
The questions hit hard:
- "Works for 15, 30, 50 lawyers… but does it work for 10,000?"
- "Human validation is expensive. How do I reduce this bottleneck?"
- "Accuracy only at deploy? How do I measure at runtime?"
- "What if the LLM breaks tomorrow at 4 AM — when do I find out?"
V0 had fulfilled its mission.
Now I needed to advance: scale, observability, quality, automation.
🧩 V1 architecture blueprint (diagram + explanation):
V1 Engineering Evolution Blueprint
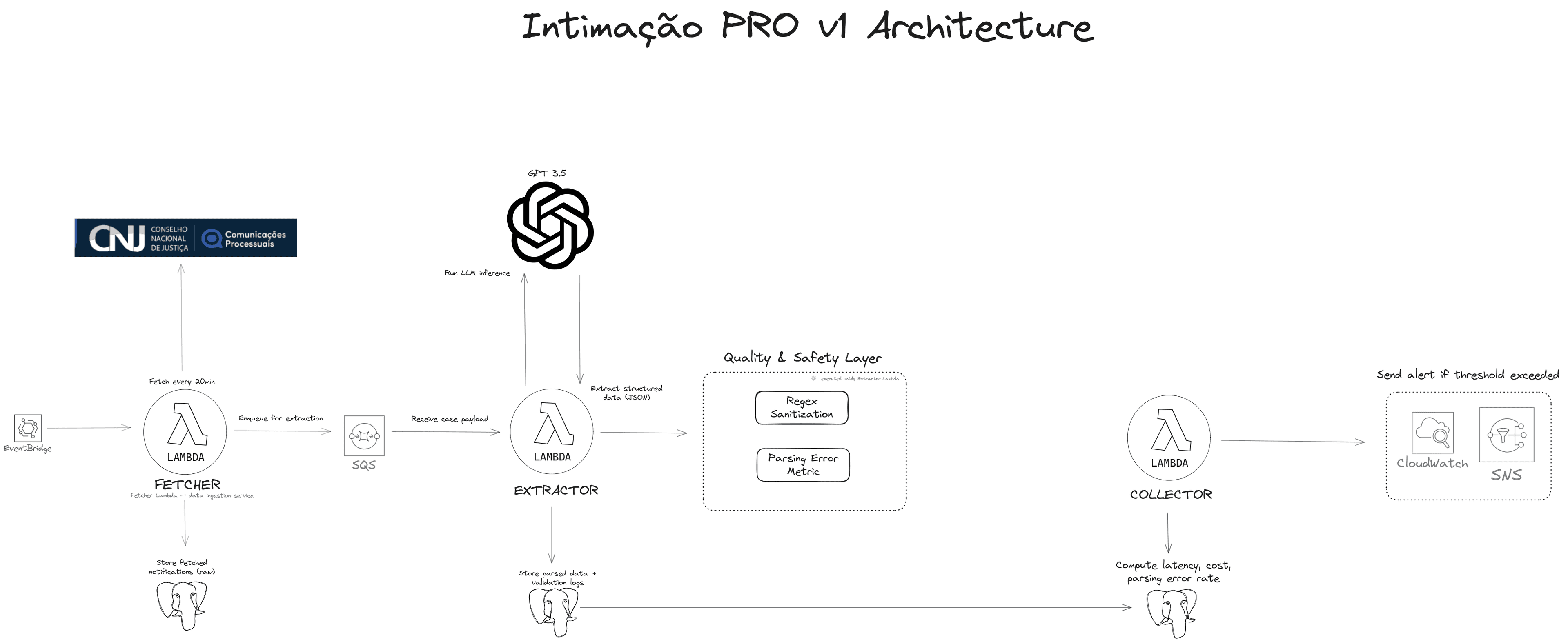
The Decision: Divide and Conquer
I took the monolith and split it into three independent functions —
Fetch, Extractor, and Collector — all connected via SQS.
Simple layers, but highly resilient:
Fetch Lambda
- Fetches notifications every 20 minutes (EventBridge).
- Isolates the data fetch.
- Independent retries.
- Zero impact on the rest of the pipeline.
Extractor Lambda
- Cleans text.
- Calls the LLM.
- Validates JSON.
- Logs parsing errors.
- Sends clean outputs to the pipeline.
Collector Lambda
- Gathers production metrics (latency, cost, parsing error rate).
- Triggers CloudWatch alerts when something exceeds expectations.
- Acts as the system's "vital pulse."
ℹ️ Latency Note:
p95/p99 weren't critical in V0 — the flow isn't interactive.
The critical metric was average latency (~4.5s), sufficient to maintain daily SLA.
Result:
decoupled, traceable, auditable, cheap.
Why Lambda and not ECS/Fargate?
For this workload (event-driven, short, CPU-bound, no heavy dependencies), Lambda delivers:
- lower cost,
- zero maintenance,
- fast deployment,
- automatic retries,
- irrelevant cold start for this use case.
🧩 Technical Decision — GPT-3.5 vs GPT-4
GPT-4 brought only ~5–7 pp accuracy gain in initial tests.
In contrast, cost increased ~12× and latency ~3×.
For a daily high-recurrence workload, GPT-3.5 was the sweet spot:
sufficient accuracy → minimal cost → stable latency.
Quality and Security Layer
Before the model runs, everything passes through a filter:
- Regex sanitization → blocks prompt injection and corrupted text.
- Parsing Error Rate → my accuracy "heartbeat."
- CloudWatch + OpenTelemetry → every call becomes an auditable event.
It's not magic.
It's observable engineering.
Reducing Human Effort: Dual Inference
To avoid overwhelming the lawyer with manual reviews:
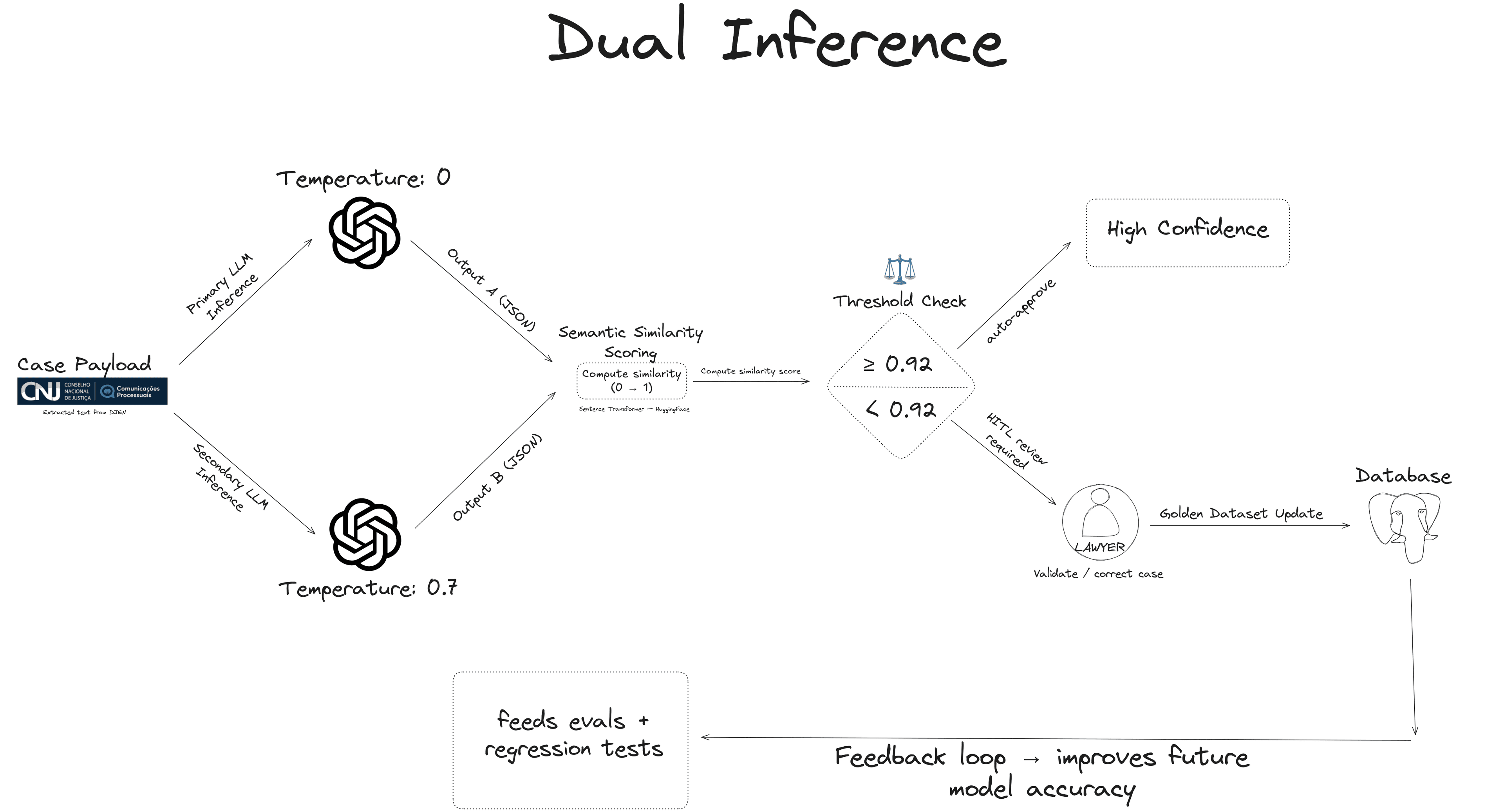
# Dual-inference mechanism (production-tested)
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
def dual_inference(payload):
r1 = llm.generate(payload, temperature=0.0)
r2 = llm.generate(payload, temperature=0.7)
emb1 = model.encode(r1, convert_to_tensor=True)
emb2 = model.encode(r2, convert_to_tensor=True)
similarity = float(util.cos_sim(emb1, emb2)[0][0])
return {
"final": r1 if similarity >= 0.90 else "HITL_REQUIRED",
"similarity": similarity,
"r1": r1,
"r2": r2
}🔀 Full dual-inference diagram (semantic similarity):
Dual Inference Pattern
- For ambiguous cases → two inferences with different temperatures (0.0 and 0.7).
- Compare both via semantic similarity (sentence-transformers/all-MiniLM-L6-v2 / Hugging Face).
- If similarity < threshold (0.90) → route to human validation.
- If ok → proceed to production automatically.
This creates a kind of "lightweight HITL":
only difficult cases reach the lawyer,
and each reviewed case feeds the golden dataset.
ℹ️ Trade-off — Dual Inference
+30% cost and +1.5s latency per analysis.
-60% human validation.
Considering the bottleneck was human (not machine),
net ROI approximately: 4× positive.
🔄 The Continuous Improvement Cycle
With this architecture, evolution became routine:
- more clean data,
- less noise,
- growing golden dataset,
- running evals,
- regression tests protecting versions,
- and accuracy climbing predictably.
Engineering moved from improvisation
into a real learning loop.
Production Metrics
Over the last five months, the system ran every single day, without interruption.
- 3,188 notifications processed
- 14 active lawyers
- 158 days of operation
- 99.22% success rate on requests
- Average cost: $0.11 per lawyer per month
- +900 hours of manual work saved

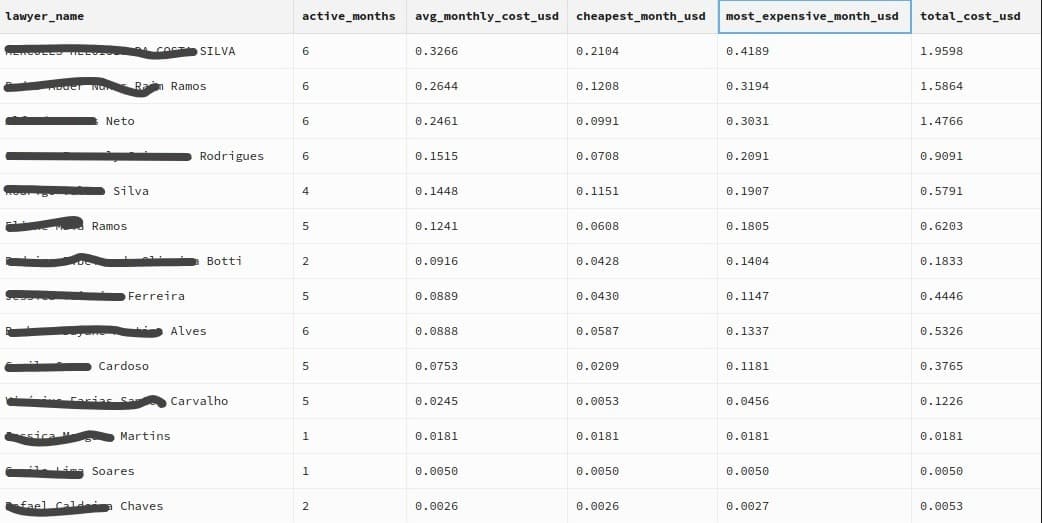
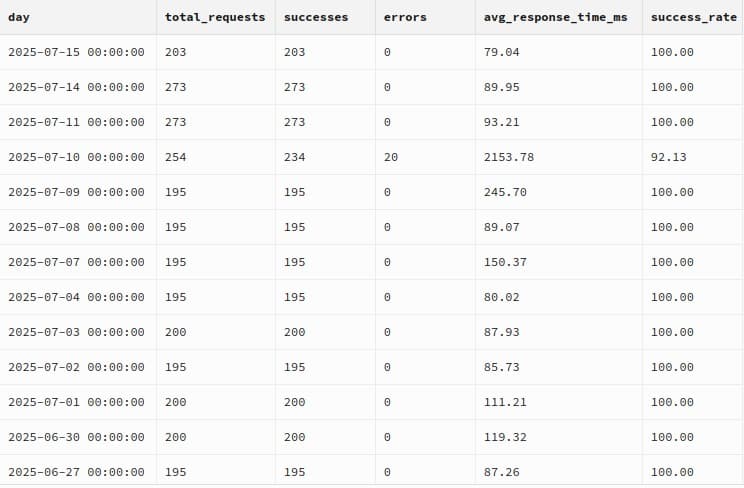
Simple numbers, but solid.
Real production. Real problems. Real impact.
The Vision
🛣️ Full roadmap (Q1 2026 →)
Future Roadmap
The pain is universal. The process is validated. The product works.
With the system validated and unit costs optimized, the focus now shifts to commercial expansion and infrastructure scale.
But the vision goes beyond:
This system can be the embryo of a complete legal assistant
for Brazilian lawyers — an agent capable of monitoring, interpreting,
responding, and acting on entire procedural flows.
And the most important part of this journey?
The clarity.
The clarity that LLMs aren't a "feature" —
they're a new layer of computational infrastructure.
And, in closed scopes, with responsible engineering,
LLMs enable automations that until recently were unfeasible — technically or economically.
Closing
In the end, Intimação Pro isn't about AI.
It's about giving lawyers back their most precious asset: time.
And for me, it was the definitive transition from Software Engineer → AI Engineer.
I'm open to conversations about AI Engineer / Tech Lead / technical co-founder roles in global remote startups.
If you need someone who takes LLMs from prototype to production at <$0.0025 per inference:

Pedro Brandão
AI Product Engineer • LLM Systems (Production)